Critical Thinking
 Die meisten Menschen würden sagen, dass die auf der Hut sind und nicht alles glauben was ihnen jemand erzählt. Meist ist dies aber nur inhaltlich der Fall, man interpretiert die Aussagen eines anderen intuitiv. Was uns die Schule oder Universität leider nicht lehr ist die Argumente des Gegenüber zu analysieren und ihre Absicht zu durchschauen um darauf angepasst reagieren zu können. Die Bildung lehrt uns kein Critical Thinking.
Die meisten Menschen würden sagen, dass die auf der Hut sind und nicht alles glauben was ihnen jemand erzählt. Meist ist dies aber nur inhaltlich der Fall, man interpretiert die Aussagen eines anderen intuitiv. Was uns die Schule oder Universität leider nicht lehr ist die Argumente des Gegenüber zu analysieren und ihre Absicht zu durchschauen um darauf angepasst reagieren zu können. Die Bildung lehrt uns kein Critical Thinking.
Mir ist das tatsächlich erst 2021 durch die bekannte Situation klar geworden, so dass ich mich intensiver mit dem Thema Critical Thinking auseinander gesetzt habe durch Video-Kurse und Bücher. Leider viel zu spät, diese Fähigkeit sollte man als Kind bereits lernen, dann hätte man es vermutlich viel leichter im Leben um Manipulation zu erkennen und zu umschiffen.
Anbei ein paar Buch-Empfehlungen zum Thema, die ich gelesen habe und die mir zugesagt haben (Links zu Amazon):
- Critical thinking, Tom Chatfield
- The Art of Thinking Clearly: The Secrets of Perfect Decision-Making, Rolf Dobelli
- Weisse Rhetorik: Überzeugen statt manipulieren, Wladislaw Jachtchenko
- Factfulness: Wie wir lernen die Welt so zu sehen, wie sie wirklich ist, Hans Rosling
In diesen Büchern lernt man
- Struktur von Argumenten, Conclusion, Prämissen, Annahmen
- Reasoning und Logik, deduktives Argumentieren
- Beobachtung, Induktives Argumentieren
- Abduction, Theorien, Hypothesen, echtes Evidenz-basiertes wissenschaftliches Denken, Korrelation und Kausalität
- Kognitive Biases
Diese Dinge sollten eigentlich in der Schule gelehrt werden, nicht dass man sie mit über 50 lernt, eigentlich dramatisch. Die Fähigkeit Argumente zu zerlegen, fehlende oder falsche Prämissen und Annahmen identifizieren zu können und Argumentation von Rhetorik zu unterscheiden, sind eigentlich Basis-Fähigkeiten die man benötigt um im Leben erfolgreich zu werden und Fehl-Entscheidungen zu vermieden.
Den Katalog von Biases im Buch von Rolf Dobelli, sollte man z.B. jedes Jahr wieder durchlesen. Weil es zu lesen und zu erkennen ist eine Sache, aber diese Erkenntnisse in der Realität (von der wir ja wissen, dass wir von ihr umzingelt sind) ist gar nicht so einfach. Meist erkennt man erst im Nachhinein, dass man in einer Situation einem solchen Bias oder argumentativen Trick aufgesessen ist. Hier hilft wohl nur Übung und eben möglichst früh sich damit zu beschäftigen. Wie es so schön heisst
Es ist nie zu spät aber selten zu früh
Sobald man Critical Thinking gelernt hat und quasi “erleuchtet” wurde, geht man plötzlich viel aufmerksamer durch die Welt. Man sollte aber darauf achten dadurch in Negativität abzugleiten sondern weiterhin positiv zu denken nur eben aufmerksamer.
Ein schönes Beispiel ist mir kürzlich untergekommen. Zusammen mit der Europawahl gibt es hier lokal auch eine kleine Volksabstimmung zum umstrittenen (im klassischen Sinne) Thema Windenergieanlagen. So wie oft ist man für erneuerbare Energien, nur nicht vor der eigenen Haustür. Aber um die inhaltliche Seite soll es hier nicht gehen.
Nun habe ich in meinem Briefkasten ein Flugblatt gefunden, wo offensichtlich die Gegner des Vorhabens Argumente bringen um die Wähler zu überzeugen gegen die Ausweisung von Flächen zu stimmen. Ein valides Unterfangen, das einer gute Argumentation bedarf.
Als ich also das Flugblatt so las, ist bei mir das Critical Thinking angesprungen und folgendes ist mir dabei aufgefallen:
- Das Bild mit den für Windkraftanlagen ausgewiesenen Flächen ist in den offiziellen städtischen Unterlagen grün markiert, im Flugblatt rot. D.h. der eine will es positiv, der andere negativ erscheinen lassen.
- Es wurden insgesamt 11 Argumente aufgezählt, was schon viel zu viel ist, Wlad würde das horizontale Argumentation nennen. Also viele Argumente zu bringen, diese aber nicht in der tiefe auszuführen. Dies ist die falsche Strategie für das Überzeugen, vertikale Argumentation wäre besser, also sich auf wenige aber gut ausgearbeitete Argumente zu konzentrieren als den Leser vielen schwachen Argumenten zu erschlagen.
- Dann war das erste Argument ein sehr schwaches Argument, es geht um die “Industralisierung des Waldes”, ein ziemlich obskuren Begriff, der ohne Erklärung den meisten wahrscheinlich eher nichts sagt. Ich würde dabei eher an die industrielle Holzbewirtschaftung denken, statt dass man einige Windräder im Wald aufbaut.
Dieses Vorgehen ist auch wieder nicht optimal, man sollte mit dem besten Argument beginnen um die Leser zu überzeugen, nicht mit einem so schwachen Argument. - Das eigentlich starke Argument für die Bürger, der potentielle Wertverlust der Immobilien “in der Nähe” der Windräder wurde erst mittendrin erwähnt, wobei Nähe relativ ist, da diese ja genau deshalb mitten im Wald mit genügend Abstand stehen, aber dieses potentielle Gegenargument wird erst gar nicht erwähnt bzw. entkräftet. Damit fehlt das Rebuttal. Das Rebuttal wäre eine wichtige Komponente einer guten Argumentation am Ende.
- Es werden zwar kurz viele Argumente ausgebreitet aber nicht in der Tiefe begründet. Das ist natürlich auf einem Flugblatt schwer zu realisieren, aber so fehlen Quellen und Fakten, die dem Leser die Argumente plausibler machen würden.
- Dann viele der Argumente enthalten implizite fehlende Prämissen, die gewissermassen als bekannt unterstellt werden, die aber nicht selbstverständlich sind. Damit wirken die Argumente für den aufmerksamen kritischen Leser sofort manipulativ, was sie wohl auch sein sollen. Aber mir ist das durch die Beschäftigung mit dem Thema Critical Thinking sofort aufgefallen und zwar äusserst negativ.
- Abgeschlossen wird das Flugblatt mit einem Appell, natürlich nicht zustimmen, kombiniert mit einem Bild der möglichen Größenverhältnisse von einem Windrad zum Stuttgarter Fernsehturm und Ulmer Münster, Gebäude mit denen sicher der lokale Bürger durchaus auskennt.
Aber es fehlen wieder die Fakten, soll den überhaupt ein so grosses Windrad auf diesen Flächen gebaut werden, oder vielleicht doch viel kleinere? Wo steht das denn? Wieder extreme implizite Annahmen, die nicht belegt werden.
Kurzum ein solches argumentatives Flugblatt wird bei achtlosen und leicht beeinflussbaren Lesern vielleicht seine Wirkung entfalten, aber bei kritischen Denkern eher das Gegenteil bewirken.
Aber das ist genau so wie die Welt heute tickt, man bemüht sich gar nicht erst den mündigen kritischen Bürger mit guten vollständigen Argumenten zu überzeugen, sondern man konzentriert sich auf manipulative Rhetorik, welche die Emotionen von Bürgern anzusprechen, die man noch wie kleine Kinder behandelt. Tagesschau-Niveau, statt lange ausführliche Diskussionen, TikTok-Minuten-Beiträge, statt 1,5h Videos.
Aber nicht mit mir, nie mehr, Critical Thinking hat mich weiter gebracht auf eine neue Stufe der persönlichen Entwicklung und das empfehle ich auch jedem, der diesen Post lesen sollte. Viel Erkenntnis daraus!
 So a couple of weeks ago I bought a book as I stumbled over it on Amazon. This week I started reading “
So a couple of weeks ago I bought a book as I stumbled over it on Amazon. This week I started reading “
 The second book from Richard Bejtlich in short time: “
The second book from Richard Bejtlich in short time: “ Wow, that was a thick book, the Tao of Network Security Monitoring, beyond intrusion detection from the guru of NSM, Richard Bejtlich. This book is considered the bible of NSM. The book is from 2004 and thus a bit out of date, especially as it is filled with tons and tons of tool, one will find that some of these do not yet exist anymore or development has stopped years ago. But the intention of the book is not to serve as a tool reference but to show which tools are available and what they can be used for. So the brain needs to translate the samples to what tools we have today available. And anyhow in each category we still have enough candidates.
Wow, that was a thick book, the Tao of Network Security Monitoring, beyond intrusion detection from the guru of NSM, Richard Bejtlich. This book is considered the bible of NSM. The book is from 2004 and thus a bit out of date, especially as it is filled with tons and tons of tool, one will find that some of these do not yet exist anymore or development has stopped years ago. But the intention of the book is not to serve as a tool reference but to show which tools are available and what they can be used for. So the brain needs to translate the samples to what tools we have today available. And anyhow in each category we still have enough candidates. Somewhere, I don’t know where, I was getting aware of the book “
Somewhere, I don’t know where, I was getting aware of the book “ This is why I recently bought the book “Modsecurity Handbook” from Feisty Duck and the authors Christian Felini and Ivan Ristić (see
This is why I recently bought the book “Modsecurity Handbook” from Feisty Duck and the authors Christian Felini and Ivan Ristić (see  Letztes Jahr hat Barbara doch tatsächlich ein eigenes Buch geschrieben, “
Letztes Jahr hat Barbara doch tatsächlich ein eigenes Buch geschrieben, “ As I’m currently involved with lots of openssl automation at work, I bought the book “Bulletproof SSL and TLS” from Ivan Ristić. See the book’s site at
As I’m currently involved with lots of openssl automation at work, I bought the book “Bulletproof SSL and TLS” from Ivan Ristić. See the book’s site at 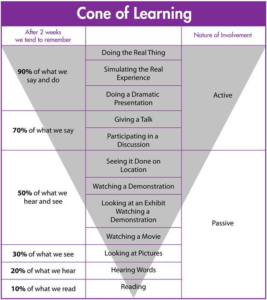 There is the model of “cone of learning” from Edgar Dale, I think. It explains how good media are for learning. The book is doing pretty bad in this model. It is passive learning and you remember only small parts of what you read. In contrast a video or podcast is remembered much more. And that is probably right in the general. How long do you remember what you read a year ago in a book? Nevertheless the depth is a different in a book in contrast to other media. and I would say it needs to stay in the learning mix also these days, electronic or not.
There is the model of “cone of learning” from Edgar Dale, I think. It explains how good media are for learning. The book is doing pretty bad in this model. It is passive learning and you remember only small parts of what you read. In contrast a video or podcast is remembered much more. And that is probably right in the general. How long do you remember what you read a year ago in a book? Nevertheless the depth is a different in a book in contrast to other media. and I would say it needs to stay in the learning mix also these days, electronic or not. 